In PostgreSQL you can switch a database from the primary server to the standby role, as well as from the standby server to the primary. This is known as a database switchover or failover. In the case of a disaster, a controlled failover can always be made manually. However, many customers prefer automated failover over manual failover as it reduces the amount of downtime and minimizes or even eliminates data loss. CYBERTEC has 20 years of experience in the field of PostgreSQL database clustering and failover.
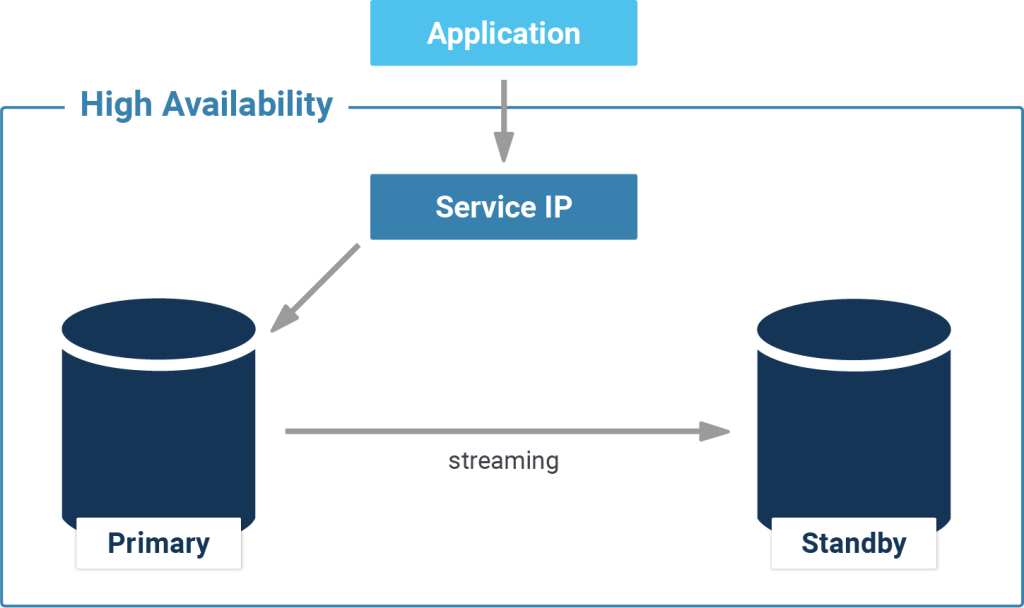
CYBERTEC recommends a combination of Patroni and vipmanager when it comes to failover and high availability for your PostgreSQL database. Advantages of this are the simple realizability and the simple handling. Learn more about this professional setup and how CYBERTEC supports you with the configuration.
Patroni’s simplicity gives it a real edge over more traditional solutions. However, many customers out there are still using traditional solutions, which are of course fully supported by CYBERTEC.
Linux HA is a general purpose solution to High-Availability as it can be used to cluster pretty much any kind of software. This kind of flexibility is also its greatest weakness because it introduces a lot of complexity, which is not necessarily desirable.
In addition to this, Patroni has been made specifically for PostgreSQL so it can use onboard functionality a lot better than Linux HA can.
However, Linux HA is still a good solution and offers a rich set of features including:
Linux HA allows PostgreSQL to integrate with other components that are required to be available around the clock.
When we talk about separate pooling servers in the PostgreSQL context, two products stand out – PgBouncer and pgpool-II. Both tools are often used in the context of PostgreSQL clustering and connection pooling.
Our database experts have written about pgpool-II and pgbouncer. For more information check out the following blog post.
In general, we recommend Patroni over pgpool-II because it is less invasive.
Slony was developed around the release date of PostgreSQL 7.4. It supports trigger-based replication. Before the introduction of transaction-log-based replications, triggers were pretty much the only way to replicate data to a set of remote hosts.
Skytools (namely a tool called londiste) faces issues that are similar to those of Slony and is therefore considered outdated. If you are interested in replicating single tables, consider checking out “CREATE PUBLICATION” and “CREATE SUBSCRIPTION”, which were introduced in PostgreSQL 10.0.
If you are using Slony and are eager to migrate or are just interested in learning about new technologies, contact us today.
Want to know more about clustering and failover? Contact us today to receive your personal offer from CYBERTEC. We offer timely delivery, professional handling, and over 20 years of PostgreSQL experience.