By Kaarel Moppel - I could make good use of the "slow time" around the turn of the year and managed to push out another set of features for our Open Source PostgreSQL monitoring tool called pgwatch2 - so a quick overview on changes in this post. Continuing the tradition, I'm calling it "Feature Pack 4" as it's mostly about new features. Git and Docker images carry version number 1.5.0. As our last pgwatch2-related blogpost covered only 1.4.0, I'll include here also most important stuff from 1.4.5 minor feature release.
This is the biggest one this time – finally and quite appropriately for "Postgres-minded" people, there's now a chance to store all the gathered metrics in Postgres! This of course doesn't necessarily mean that Postgres is best for storing Time-Series Data although it performs very nicely thanks to JSONB...but in general it's a good compromise – more disk space (~3-4x) at comparable query times to InfluxDB...but with full power of SQL! Meaning some saved time learning a new (and quite limited) query language. And after all, only a few people are running dozens and dozens of databases, so performance is mostly not an issue. And on the plus side we can now ask questions that were previously plainly not possible (no joins, remember) or were only possible by storing some extra columns of data (de-normalizing).
The new functionality is designed for the latest Postgres version of 11, but as people run all kinds of different versions and might not want to set up a new cluster, there is also a legacy mode, that will cost more IO though. In total there are 4 different "schema modes" so that people could optimize their IO based on needs:
For the partitioned modes there is also automatic "retention management" – by default 1 month of data is kept. Partitions live in a separate "subpartitions" schema, top level tables are in "public".
To test it out fire up a Docker container with something like:
|
1 2 3 4 |
# assuming 'postgres' is superuser and auto-creating metrics fetching helpers docker run --rm --name pw2 -p 3000:3000 -e PW2_ADHOC_CONN_STR='postgresql://postgres@mydb.com/mydb' -e PW2_ADHOC_CREATE_HELPERS=1 cybertec/pgwatch2-postgres # After 5min open up Grafana at 0.0.0.0:3000 and start evaluating what's going on in your database... |
And as always, please do let us know on GitHub if you’re still missing something in the tool or are experiencing difficulties - any feedback would be highly appreciated!
Project GitHub link – here.
Full changelog – here.
There are multiple (4) storage schema types supported so even legacy PG versions and custom needs should be covered. PG 11+ needed though to use time-based partitioning. Comes with automatic "retention policy" enforcement (given the gatherer is running).
A by-product of testing Postgres metrics storage, it helps to quickly estimate metrics data volumes under real life conditions to see if your hardware or selected storage "schema type" can handle the amount of planned metrics. Metrics will be fetched one time from a user specified DB and then data inserted multiple times with correct intervals for the simulated host count. There are also some scripts provided to generate bigger data amounts faster and to test typical dashboard queries speed.
Previously monitoring user passwords where stored in plain text for both "config DB" and "YAML" mode. Now an encryption key or keyfile can be provided to the Gatherer and the Web UI to transparently encrypt passwords. Default will remain "plain-text" as pgwatch2 is assumable mostly used in safe environments or for ad-hoc troubleshooting and it's just more convenient so.
Previously only 'disabled' and 'require' were supported. Certs need to be present on the machine where the gatherer is running.
For example, the "pg_stat_database_conflicts" view is always empty on a primary, so it makes no sense to query it there. This should result in less errors both in Postgres and pgwatch2 logs.
Previously "public" schema for extensions and "metric fetching helpers" was assumed, but now no such assumption is made, allowing any schema – user just needs to make sure that the monitoring role has it's "search_path" correctly set. Also, no more "public" grants for helpers, only for the monitoring role.
Paths need to be adjusted manually both for the Gatherer and Web UI. Thanks @slardiere!
50% less internal message passing over channels meaning much better performance when monitoring 50+ DB-s.
Also, when metric definitions are not found etc, one error per hour only.
Some new metrics ("wal_size") added and "db_size" split up from "db_stats". Gathering intervals for some "not so used" metrics have also been increased in the preset configs.
Two different metric queries can now run simultaneously on a single monitored DB.
All most important health indicators on a singe page, with green / yellow / red indicators.
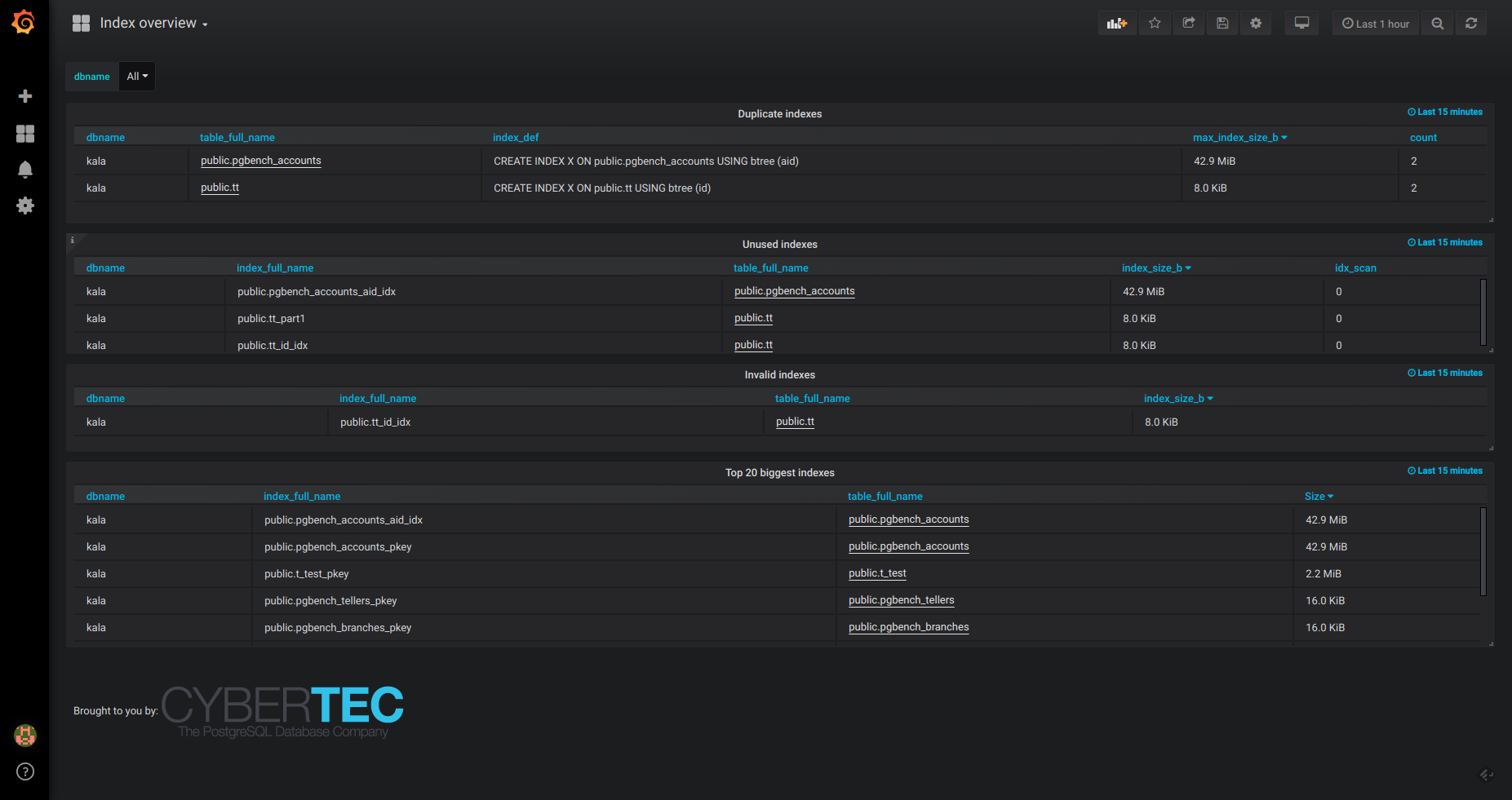
Top scanned, un-used, biggest, duplicate and invalid indexes overview.
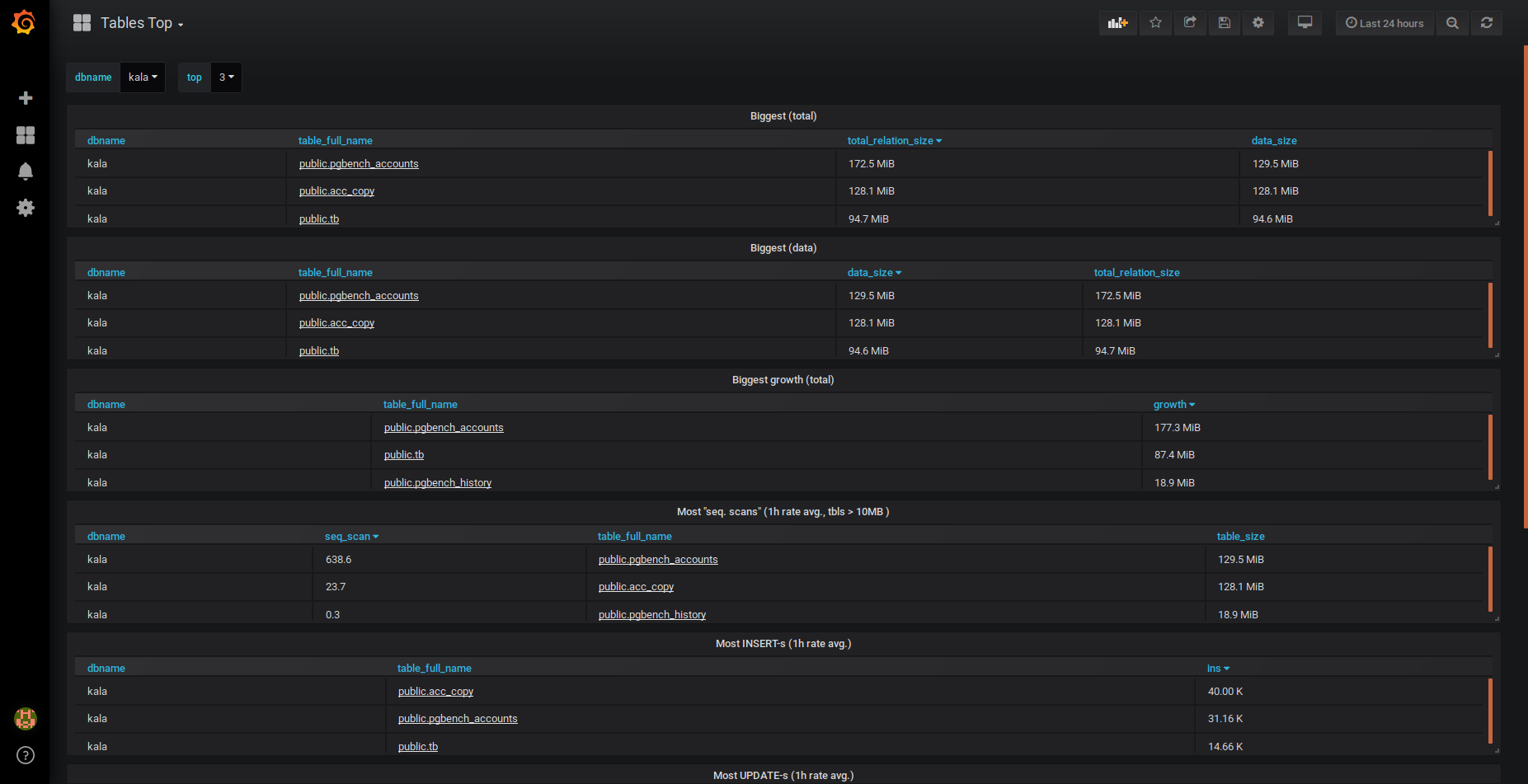
Top-N by size and growth/scan and INSERT/UPDATE/DELETE rates.
pgwatch2 is constantly being improved and new features are added. Learn more >>

Security is an important topic. This is not only true in the PostgreSQL world – it holds truth for pretty much any modern IT system. Databases, however, have special security requirements. More often than not confidential data is stored and therefore it makes sense to ensure that data is protected properly. Security first! This blog post describes the extension pg_permissions, which helps you to get an overview of the permissions in your PostgreSQL database.
Gaining an overview of all permissions granted to users in PostgreSQL can be quite difficult. However, if you want to secure your system, gaining an overview is really everything – it can be quite easy to forget a permission here and there and fixing things can be a painful task. To make life easier, Cybertec has implemented pg_permissions (https://github.com/cybertec-postgresql/pg_permissions). There are a couple of things which can be achieved with pg_permissions:
However, let us get started with the simple case – listing all permissions. pg_permissions provides a couple of views, which can be accessed directly once the extension has been deployed. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
test=# \x Expanded display is on. test=# SELECT * FROM all_permissions WHERE role_name = 'workspace_owner'; -[ RECORD 1 ]------------------------------------------------------- object_type | TABLE role_name | workspace_owner schema_name | public object_name | b column_name | permission | SELECT granted | t -[ RECORD 2 ]------------------------------------------------------- object_type | TABLE role_name | workspace_owner schema_name | public object_name | b column_name | permission | INSERT granted | t -[ RECORD 3 ]------------------------------------------------------- object_type | TABLE role_name | workspace_owner schema_name | public object_name | b column_name | permission | UPDATE granted | f |
The easiest way is to use the “all_permissions” view to gain an overview of EVERYTHING. However, if you are only interested in function, tables, columns, schemas and so on there are more views, which you can use. “all_permissions” will simply show you all there is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE VIEW all_permissions AS SELECT * FROM table_permissions UNION ALL SELECT * FROM view_permissions UNION ALL SELECT * FROM column_permissions UNION ALL SELECT * FROM sequence_permissions UNION ALL SELECT * FROM function_permissions UNION ALL SELECT * FROM schema_permissions UNION ALL SELECT * FROM database_permissions; |
Securing your application is not too hard when your application is small – however, if your data model is changing small errors and deficiencies might sneak in, which can cause severe security problems in the long run. pg_permissions has a solution to that problem: You can declare, how the world is supposed to be. What does that mean? Here is an example: “All bookkeepers should be allowed to read data in the bookkeeping schema.” or “Everybody should have USAGE permissions on all schemas”. What you can do now is to compare the world as it is with the way you want it to be. Here is how it works:
|
1 2 3 4 |
INSERT INTO public.permission_target (id, role_name, permissions, object_type, schema_name) VALUES (3, 'appuser', '{USAGE}', 'SCHEMA', 'appschema'); |
The user also needs USAGE privileges on the appseq sequence in that schema:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
INSERT INTO public.permission_target (id, role_name, permissions, object_type, schema_name, object_name) VALUES (4, 'appuser', '{USAGE}', 'SEQUENCE', 'appschema', 'appseq'); SELECT * FROM public.permission_diffs(); missing | role_name | object_type | schema_name | object_name | column_name | permission ---------+-----------+-------------+-------------+-------------+-------------+------------ f | hans | VIEW | appschema | appview | | SELECT t | appuser | TABLE | appschema | apptable | | DELETE (2 rows) |
You will instantly get an overview and see, which differences between your desired state and your current state exist. By checking the differences directly during your deployment process, our extension will allow you to react and fix problems quickly.
Once you have figured out, which permissions there are, which ones might be missing or which ones are wrong, you might want to fix things. Basically, there are two choices: You can fix stuff by hand and assign permissions one by one. That can be quite a pain and result in a lot of work. So why not just update your “all_permissions” view directly? pg_permissions allows you to do exactly that … You can simply update your views and pg_permissions will execute the desired changes for you (fire GRANT and REVOKE statements behind the scene). This way you can change hundreds or even thousands of permission using a simple UPDATE statement. Securing your database has never been easier.
Many people are struggling with GRANT and REVOKE statements. Therefore, being able to use UPDATE might make life easier for many PostgreSQL users out there.
We want to make pg_permissions even better: if there are any cool ideas out there, don’t hesitate to contact us anytime. We are eagerly looking for new ideas and even better concepts.
For more info about security and permissions in PostgreSQL, read our other blog posts.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.

UPDATED August 2024
pgbouncer is the most widely used connection pooler for PostgreSQL.
This blog will provide a simple cookbook recipe for how to configure user authentication with pgbouncer.
I wrote this cookbook using Fedora Linux and installed pgbouncer using the PGDG Linux RPM packages available from the download site.
But it should work pretty similarly anywhere.
Setting max_connections to a high value can impact performace and can even bring your database to its knees if all these connections become active at the same time.
Also, if database connections are short-lived, a substantial amount of your database resources can be wasted just opening database connections.
To mitigate these two problems, we need a connection pooler. A connection pooler is a proxy between the client and the database: clients connect to the connection pooler, which handles the SQL requests via a relatively stable set of persistent database connections (the “connection pool”).
Since clients connect to pgbouncer, it will have to be able to authenticate them, so we have to configure it accordingly.
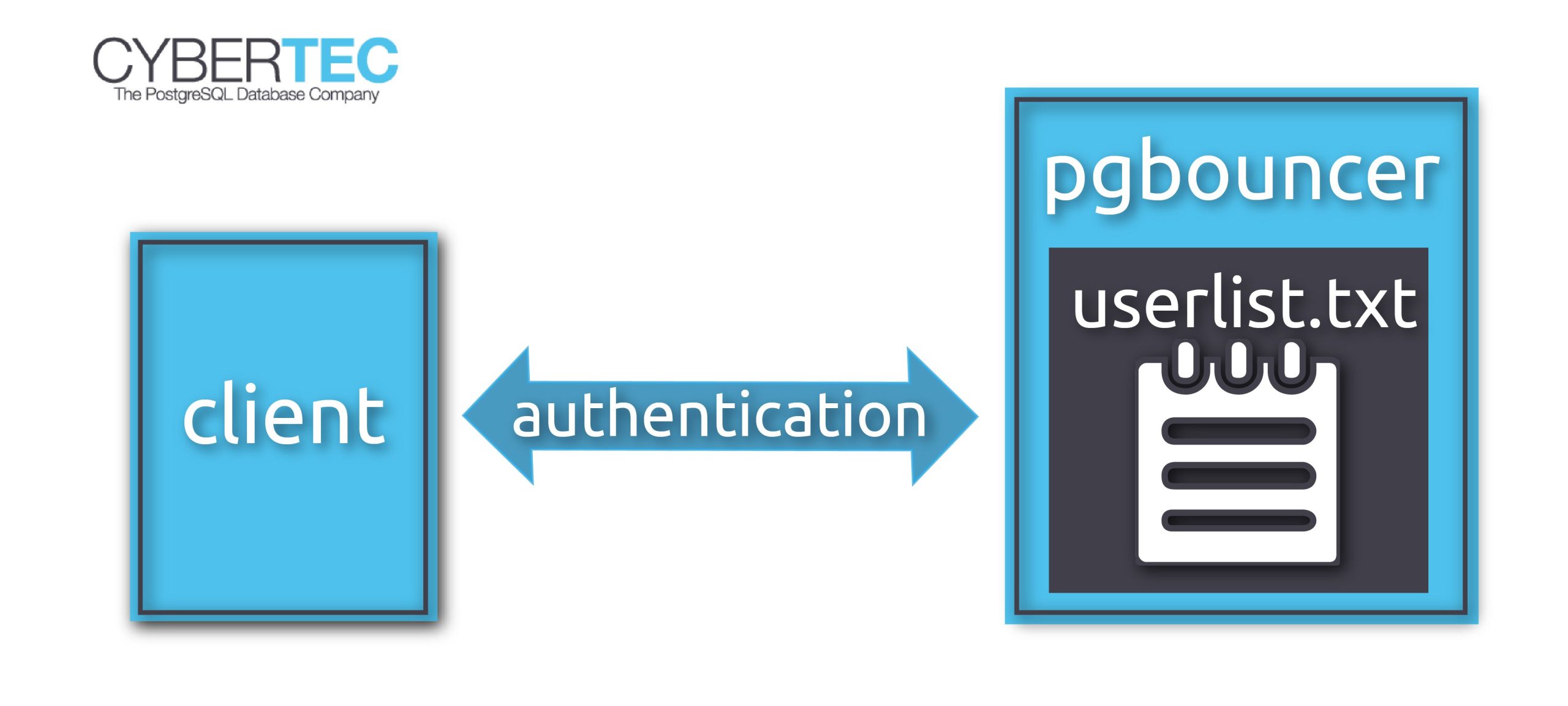 This method is useful if the number of database users is small and passwords don't change frequently.
This method is useful if the number of database users is small and passwords don't change frequently.
For that, we create a configuration file userlist.txt in the pgbouncer configuration directory (on my system /etc/pgbouncer).
The file contains the database users and their passwords, so that pgbouncer can authenticate the client without resorting to the database server.
It looks like this:
|
1 2 |
'laurenz' 'md565b6fad0e85688f3f101065bc39552df' 'postgres' 'md553f48b7c4b76a86ce72276c5755f217d' |
You can write the file by hand using the information from the pg_shadow catalog table, or you can create it automatically.
For that to work, you need
psqlPATH, you'll have to use the absolute path (something like /usr/pgsql-11/bin/psql or "C:Program FilesPostgreSQL11binpsql").root user or administratorThen you can simply create the file like this:
|
1 |
psql -Atq -U postgres -d postgres -c 'SELECT concat(''', usename, '' '', passwd, ''') FROM pg_shadow' |
Once you have created userlist.txt, add the following to the [pgbouncer] section of /etc/pgbouncer/pgbouncer.ini:
|
1 2 3 |
[pgbouncer] auth_type = md5 auth_file = /etc/pgbouncer/userlist.txt/userlist.txt |
Done!
Note: the above example uses md5 authentication, which is pretty much obsolete now. Instead, you should be using scram-sha-256. For that to work, you have to use a password hashed with scram-sha-256 in userlist.txt. You cannot use the trick above to generate these hashes. Instead, query the catalog table pg_authid for the actual password hashes. See my article about moving from md5 authentication to scram-sha-256 for more information.
 If users and passwords change frequently, it would be annoying to have to change the user list all the time.
If users and passwords change frequently, it would be annoying to have to change the user list all the time.
In that case it is better to use an “authentication user” that can connect to the database and get the password from there.
You don't want everyone to see your database password, so we give access to the passwords only to this authentication user.
Using psql, we connect to the database as superuser and run the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE ROLE pgbouncer LOGIN; -- set a password for the user password pgbouncer CREATE FUNCTION public.lookup ( INOUT p_user name, OUT p_password text ) RETURNS record LANGUAGE sql SECURITY DEFINER SET search_path = pg_catalog AS $$SELECT usename, passwd FROM pg_shadow WHERE usename = p_user$$; -- make sure only 'pgbouncer' can use the function REVOKE EXECUTE ON FUNCTION public.lookup(name) FROM PUBLIC; GRANT EXECUTE ON FUNCTION public.lookup(name) TO pgbouncer; |
pg_shadow is only accessible to superusers, so we create a SECURITY DEFINER function to give pgbouncer access to the passwords.
Then we have to create a userlist.txt file as before, but it will only contain a single line for user pgbouncer.
The configuration file in /etc/pgbouncer/pgbouncer.ini should look like this:
|
1 2 3 4 5 |
[pgbouncer] auth_type = scram-sha-256 auth_file = /etc/pgbouncer/userlist.txt auth_user = pgbouncer auth_query = SELECT p_user, p_password FROM public.lookup($1) |
Now whenever you authenticate as a user other than pgbouncer, the database will be queried for the current password of that user.
Since the auth_query connection will be made to the destination database, you need to add the function to each database that you want to access with pgbouncer.
pg_hba.confYou can determine which connections pgbouncer will accept and reject using a pg_hba.conf file like in PostgreSQL, although pgbouncer only accepts a subset of the authentication methods provided by PostgreSQL.
To allow connections only from two application servers, the file could look like this:
|
1 2 3 |
# TYPE DATABASE USER ADDRESS METHOD host mydatabase appuser 72.32.157.230/32 scram-sha-256 host mydatabase appuser 217.196.149.50/32 scram-sha-256 |
If the file is called /etc/pgbouncer/pg_hba.conf, your pgbouncer.ini would look like this:
|
1 2 3 4 |
[pgbouncer] auth_type = scram-sha-256 auth_hba_file = /etc/pgbouncer/pg_hba.conf auth_file = /etc/pgbouncer/userlist.txt |
You can of course also use auth_query in that case.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
I once received a mail with question: Can you tell me why I can't select the column references?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
=# d v_table_relation View 'public.v_table_relation' Column | Type | Collation | Nullable | Default ------------+-------------------------------------+-----------+----------+--------- schema | information_schema.sql_identifier | | | table | information_schema.sql_identifier | | | columns | information_schema.sql_identifier[] | | | references | jsonb[] | | | =# select * from v_table_relation ; schema | table | columns | references -----------+------------+-----------------+-------------------------------------------------------------------------------------------------------------------- public | a | {b,c} | {} public | a2 | {b,c} | {'{'toTable': 'a', 'toSchema': 'public', 'toColumns': ['b', 'c'], 'fromColumns': ['b', 'c']}'} workspace | t_employee | {id,name,state} | {} (3 rows) =# select references from v_table_relation; ERROR: syntax error at or near 'references' LINE 1: select references from v_table_relation; |
Well, the quick answer will be: because REFERENCES is a keyword you should use double quotes around it, e.g.
=# select references from v_table_relation;
As usual one may find the answers in the PostgreSQL manual:
www.postgresql.org/docs/current/sql-keywords-appendix.html
There we have detailed table that lists all tokens that are key words in the SQL standard and in PostgreSQL. From the manual you will know about reserved and non-reserved tokens, SQL standard compatibility and much more which is out of scope of this post.
There are two more ways to know what tokens can or cannot be used in certain situations. First is for true programmers, and the second is for true admins. Choose your pill, Neo.
PostgreSQL uses LALR(1)* parser to work with SQL statements. Implementation of the grammar (parser itself) may be found in the gram.y and implementation of the lexical analyzer (lexer) in the scan.l file.
Query first chewed to by lexer, which splits the text into tokens and sends them to the parser. It is logical to assume that lexer is the first who knows if the token is a keyword or not. Examining the source of it we find such lines:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
... {identifier} { const ScanKeyword *keyword; char *ident; SET_YYLLOC(); /* Is it a keyword? */ keyword = ScanKeywordLookup(yytext, yyextra->keywords, yyextra->num_keywords); if (keyword != NULL) { yylval->keyword = keyword->name; return keyword->value; } /* * No. Convert the identifier to lower case, and truncate * if necessary. */ ident = downcase_truncate_identifier(yytext, yyleng, true); yylval->str = ident; return IDENT; } ... |
So, the lexer knows if the identifier is a keyword, but this doesn't give us much, since during lexical analyzis we're lacking context. And that is what parser takes care of.
Our journey started from simple SELECT statement producing error, so let's try to examine gram.y from the top to bottom. Our route will be like this:
stmtblock -> stmtmulti -> stmt -> CreateStmt
OptTableElementList -> TableElementList -> TableElement -> columnDef -> ColId
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
/* * Name classification hierarchy. * * IDENT is the lexeme returned by the lexer for identifiers that match * no known keyword. In most cases, we can accept certain keywords as * names, not only IDENTs. We prefer to accept as many such keywords * as possible to minimize the impact of "reserved words" on programmers. * So, we divide names into several possible classes. The classification * is chosen in part to make keywords acceptable as names wherever possibl */ /* Column identifier --- names that can be column, table, etc names. */ ColId: IDENT { $ = $1; } | unreserved_keyword { $ = pstrdup($1); } | col_name_keyword { $ = pstrdup($1); } ; |
By the way, I'm absolutely sure PostgreSQL sources are the best academic reading in the world. From here we see that we want to accept as much "reserved" keywords as possible, but this produces difficulties in different places causing grammar conflicts (reducereduce mostly, because shiftreduce are solved automatically). Thus, to prevent these errors developers divided keywords into several classes, e.g. "unreserved_keyword" and "col_name_keyword". And only one step left: to find these classes. Piece of cake! Let's check "unreserved_keyword" node:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
... /* * Keyword category lists. Generally, every keyword present in * the Postgres grammar should appear in exactly one of these lists. * * Put a new keyword into the first list that it can go into without causing * shift or reduce conflicts. The earlier lists define "less reserved" * categories of keywords. * * Make sure that each keyword's category in kwlist.h matches where * it is listed here. (Someday we may be able to generate these lists and * kwlist.h's table from a common master list.) */ /* "Unreserved" keywords --- available for use as any kind of name. */ unreserved_keyword: ABORT_P ... /* Column identifier --- keywords that can be column, table, etc names. * * Many of these keywords will in fact be recognized as type or function * names too; but they have special productions for the purpose, and so * can't be treated as "generic" type or function names. * * The type names appearing here are not usable as function names * because they can be followed by '(' in typename productions, which * looks too much like a function call for an LR(1) parser. */ col_name_keyword: BETWEEN ... /* Type/function identifier --- keywords that can be type or function names. * * Most of these are keywords that are used as operators in expressions; * in general such keywords can't be column names because they would be * ambiguous with variables, but they are unambiguous as function identifiers. * * Do not include POSITION, SUBSTRING, etc here since they have explicit * productions in a_expr to support the goofy SQL9x argument syntax. * - thomas 2000-11-28 */ type_func_name_keyword: AUTHORIZATION ... /* Reserved keyword --- these keywords are usable only as a ColLabel. * * Keywords appear here if they could not be distinguished from variable, * type, or function names in some contexts. Don't put things here unless * forced to. */ reserved_keyword: ALL ... ; %% |
There is one more way knowing how restrictive keyword usage is: execute query
SELECT * FROM pg_get_keywords();
Function pg_get_keywords() returns list of SQL keywords and their categories:
The catcode column contains a category code: U for unreserved, C for column name, T for type or function name, or R for reserved. The catdesc column contains a possibly-localized string describing the category.
If you need assistantance - please feel free to contact us!