Many people who have used PostgreSQL or SQL in general in a professional or semi-professional way have stumbled across “aggregate functions”. A database engine such as PostgreSQL usually provides the most basic aggregate functions such as count, min, max, sum, and so on. However, those functions are pretty limited and fulfil only the basic needs and requirements. In many cases those basic functions are not enough, and it makes sense to create your own code to make sure that calculations can still be done on the server side.
Table of Contents
People might argue now: Why not move the business logic out of the database and do things on the application level? Well: In many cases the answer might be easy. Suppose you have 10 billion rows in your PostgreSQL database, and you want to do a simple calculation. Having the computation on the client (maybe in a Java application or so) requires the transfer of the data from the database to the application. Suppose each row is merely 100 bytes. The amount of data you had to move around is staggering:
|
1 2 3 4 5 |
test=# SELECT pg_size_pretty(10000000000 * 100); pg_size_pretty ---------------- 931 GB (1 row) |
You have to move close to 1 TB of data just to make some Java design pattern happy. Therefore it can make sense to calculate stuff on the server side because you can avoid moving all the data around over the network. Doing things in SQL is just fine and will ensure that only the results have to be transported over the wire, which is a major advantage over doing things on the client side. In many cases the results of a calculation are not too big anyway.
Fortunately, PostgreSQL is really flexible and allows end users to create your own aggregation functions, which can help to move your business logic to PostgreSQL. The “CREATE AGGREGATE” command is there to create all kinds of aggregations. This blog post does not cover all the details but shows how to implement the most simplistic example. Maybe we will cover some more details in a future blog post. However, what you see here should help you to getting started.
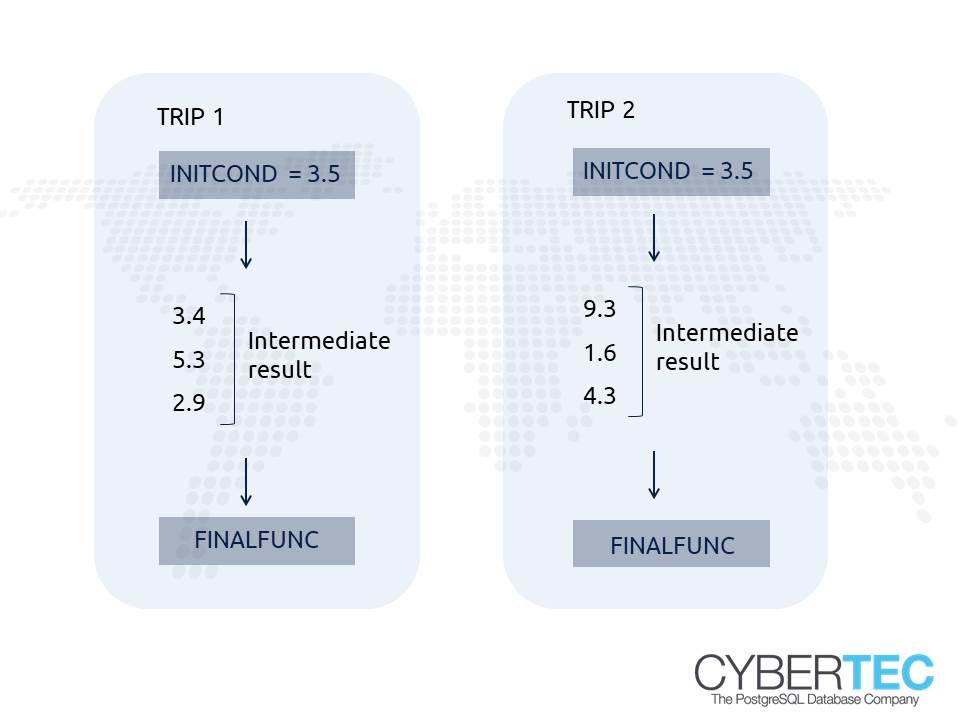
To show how things work, I decided to include a very simple example: Suppose we want to calculate the total price of a taxi ride. Hopping on the taxi will cost you EUR 3.50 and for every kilometer we add EUR 2.20 to the price. At the end of the day, we want to round up the price to tip the taxi driver. The goal is to calculate the price for each ride.
Here is some sample data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE t_taxi ( trip_id int, km numeric ); COPY t_taxi FROM stdin DELIMITER ';'; 1;3.4 1;5.3 1;2.9 2;9.3 2;1.6 2;4.3 . |
In this example I have added data for two trips. Let us assume for the sake of simplicity that every trip simply consists of a couple of segments. What we want to do now is to add up those segments and calculate the entire price for each step.
To do that we basically need two functions: One function is called for each row (the “SFUNC”) and the second one is called once for each group (let us simply call it “FINALFUNC”):
|
1 2 3 4 5 |
CREATE FUNCTION taxi_accum (numeric, numeric, numeric) RETURNS numeric AS $ SELECT $1 + $2*$3; $ LANGUAGE 'sql' STRICT; |
What the function does is to take the intermediate value from all previous calls (= the first parameter) and data from the current row. The function is called once per row.
At the end of the group the “FINALFUNC” is called:
|
1 2 3 4 5 |
CREATE FUNCTION taxi_final(numeric) RETURNS numeric AS $ SELECT round($1 + 5, -1); $ LANGUAGE 'sql' STRICT; |
In our example this means:
|
1 2 3 4 5 6 7 8 9 |
x = taxi_accum(INITCOND = 3.5, 3.4, 2.20) x = taxi_accum(x, 5.3, 2.20) x = taxi_accum(x, 2.9, 2.20) result_value_1 = taxi_final(x) x = taxi_accum(INITCOND = 3.5, 9.3, 2.20) x = taxi_accum(x, 1.6, 2.20) x = taxi_accum(x, 4.3, 2.20) result_value_2 = taxi_final(x) |
Two rows (one for each group) will be returned.
After introducing the basic logic we can already create the aggregate. In my example the aggregate takes two parameters: One for the number of kilometers per segment and one for the price per kilometer. The price to hire the taxi is EUR 3.50, which is reflected by the INITCOND (= start value of each group):
|
1 2 3 4 5 6 7 |
CREATE AGGREGATE taxi(numeric, numeric) ( INITCOND = 3.50, STYPE = numeric, SFUNC = taxi_accum, FINALFUNC = taxi_final ); |
Basically creating the aggregate is easy: It needs to know the parameters it takes; it must know how to get started, we got to tell it the data type of the intermediate result as well as the functions, which have to be called (for each line and at the end of the group).
Once the aggregate has been deployed in your PostgreSQL database, you can already run a simple query:
|
1 2 3 4 5 6 7 8 9 10 |
test=# SELECT trip_id, taxi(km, 2.20), 3.50 + sum(km)*2.2 AS manual FROM t_taxi GROUP BY 1; trip_id | taxi | manual ---------+------+-------- 2 | 40 | 36.94 1 | 30 | 29.02 (2 rows) |
In this the custom aggregate has been called along with some manual magic to verify the correctness of the data.
The beauty is that you can use the very same system to handle grouping sets and alike. Here is an example:
|
1 2 3 4 5 6 7 8 9 |
SELECT trip_id, taxi(km, 2.20), 3.50 + sum(km)*2.2 AS manual FROM t_taxi GROUP BY ROLLUP(1); trip_id | taxi | manual ---------+------+-------- 1 | 30 | 29.02 2 | 40 | 36.94 | 70 | 62.46 |
The last row gives us the value assuming that the entire thing was really just one trip instead of 2. So basically there are 3 aggregates returned by the query. There are no special precautions needed. The aggregate just works. The same is true for window functions and analytics.
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Facebook or LinkedIn.
+43 (0) 2622 93022-0
office@cybertec.at
You are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from X. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information
Good article - and another example for such a fantastic DB-System!