This post shows how to optimize a slow query that came out of the Reproducible Builds project. The Reproducible Builds initiative aims to make software compilation entirely deterministic, with no
variation in the output when the build is run again. This makes software supply chain attacks much harder, but has also advantages for software quality assurance. While initially started by Debian, reproducible builds are now part of many other Linux distributions and software projects like Alpine, Apache Maven, Arch, Buildroot, coreboot, Fedora, F-Droid, FreeBSD, GNU Guix, NetBSD, NixOS, openSUSE, OpenWrt, Qubes, Tails, Tor Browser, and many others.
Table of Contents

To check if some given software package is reproducible, rebuilders run that build with some environment variations, and compare the build results. For example, the time on one of the build machines runs ahead, to check if some "built on this date" stamp is embedded in the build result. Naturally, this machinery includes a PostgreSQL database which stores the "is package X reproducible?" information. Rebuilds are triggered periodically, and again, this involves SQL queries.
Some time ago, I was asked by a fellow Debian Developer to look at a query which performed particularly badly: determining which packages to test next took around 45 minutes.
The query had already been found:
|
1 2 3 4 5 6 7 8 9 10 11 |
query = '''SELECT DISTINCT * FROM ( SELECT sources.id, sources.name FROM sources WHERE sources.suite='{suite}' AND sources.architecture='{arch}' AND sources.id NOT IN (SELECT schedule.package_id FROM schedule WHERE build_type='ci_build') AND sources.id NOT IN (SELECT results.package_id FROM results) ORDER BY random() ) AS tmp LIMIT {limit}'''.format(suite=suite, arch=arch, limit=limit) |
I loaded up the provided database dump and looked at the execution plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
Limit (cost=209073033.46..209073034.58 rows=150 width=19) -> Unique (cost=209073033.46..209073096.74 rows=8438 width=19) -> Sort (cost=209073033.46..209073054.55 rows=8438 width=19) Sort Key: tmp.id, tmp.name -> Subquery Scan on tmp (cost=209072377.71..209072483.19 rows=8438 width=19) -> Sort (cost=209072377.71..209072398.81 rows=8438 width=27) Sort Key: (random()) -> Gather (cost=28821.92..209071827.44 rows=8438 width=27) Workers Planned: 2 -> Parallel Bitmap Heap Scan on sources (cost=27821.92..209069962.55 rows=3516 width=19) Recheck Cond: ((suite = 'trixie'::text) AND (architecture = 'amd64'::text)) Filter: ((NOT (hashed SubPlan 1)) AND (NOT (SubPlan 2))) -> Bitmap Index Scan on sources_new_name_suite_architecture_key (cost=0.00..27602.19 rows=33754 width=0) Index Cond: ((suite = 'trixie'::text) AND (architecture = 'amd64'::text)) SubPlan 1 -> Seq Scan on schedule (cost=0.00..194.00 rows=9280 width=4) Filter: (build_type = 'ci_build'::build_type) SubPlan 2 -> Materialize (cost=0.42..27738.62 rows=795010 width=4) -> Index Only Scan using results_tmp_package_id_key1 on results (cost=0.42..20657.58 rows=795010 width=4) JIT: Functions: 24 Options: Inlining true, Optimization true, Expressions true, Deforming true |
The 9-digit estimated plan cost and subsequently the 45min query run time come from the O(N²) behavior of the two SubPlans in there.
The problem is so common that it got a place on PostgreSQL's famous Don't Do This list:
Don't use NOT IN
.
"...performance can look good in small-scale tests but then slow down by 5 or more orders of magnitude once a size threshold is crossed; you do not want this to happen."
As Laurenz explained in his subqueries in PostgreSQL blog post, the optimizer cannot rewrite NOT IN (subquery) to something else, since that would change the query semantics. But since we know we do not care about NULLs here, we can rewrite the query manually to use NOT EXISTS (subquery):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
EXPLAIN (ANALYZE) SELECT DISTINCT * FROM ( SELECT sources.id, sources.name FROM sources WHERE sources.suite='trixie' AND sources.architecture='amd64' AND NOT EXISTS ( SELECT FROM schedule WHERE build_type = 'ci_build' AND sources.id = schedule.package_id ) AND NOT EXISTS ( SELECT FROM results WHERE sources.id = results.package_id ) ORDER BY random() ) AS tmp LIMIT 150; QUERY PLAN ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── Limit (cost=24069.15..24069.39 rows=32 width=19) (actual time=95.414..99.711 rows=0 loops=1) -> Unique (cost=24069.15..24069.39 rows=32 width=19) (actual time=95.412..99.709 rows=0 loops=1) -> Sort (cost=24069.15..24069.23 rows=32 width=19) (actual time=95.393..99.689 rows=0 loops=1) Sort Key: tmp.id, tmp.name Sort Method: quicksort Memory: 25kB -> Subquery Scan on tmp (cost=24067.95..24068.35 rows=32 width=19) (actual time=95.386..99.683 rows=0 loops=1) -> Sort (cost=24067.95..24068.03 rows=32 width=27) (actual time=95.385..99.681 rows=0 loops=1) Sort Key: (random()) Sort Method: quicksort Memory: 25kB -> Gather (cost=1000.71..24067.15 rows=32 width=27) (actual time=95.381..99.677 rows=0 loops=1) Workers Planned: 2 Workers Launched: 2 -> Nested Loop Anti Join (cost=0.71..23063.87 rows=13 width=19) (actual time=67.901..67.902 rows=0 loops=3) -> Nested Loop Anti Join (cost=0.42..23059.71 rows=13 width=19) (actual time=58.194..67.893 rows=2 loops=3) -> Parallel Seq Scan on sources (cost=0.00..13057.60 rows=14064 width=19) (actual time=19.630..43.509 rows=11564 loops=3) Filter: ((suite = 'trixie'::text) AND (architecture = 'amd64'::text)) Rows Removed by Filter: 253695 -> Index Only Scan using results_tmp_package_id_key1 on results (cost=0.42..0.70 rows=1 width=4) (actual time=0.002..0.002 rows=1 loops=34692) Index Cond: (package_id = sources.id) Heap Fetches: 0 -> Index Scan using schedule_tmp_package_id_key on schedule (cost=0.29..0.32 rows=1 width=4) (actual time=0.004..0.004 rows=1 loops=5) Index Cond: (package_id = sources.id) Filter: (build_type = 'ci_build'::build_type) Planning Time: 1.182 ms Execution Time: 99.798 ms |
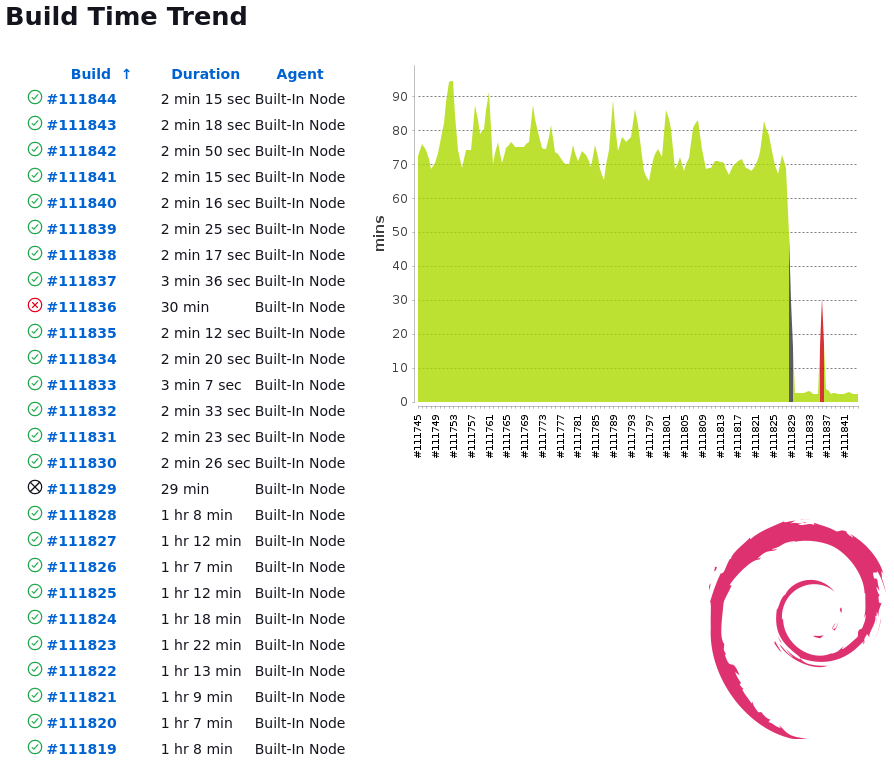
100ms looks much better. Compared to the original 45min runtime, that's a 27,000x speedup.
In practice, the job running this query now runs much faster:
In order to receive regular updates on important changes in PostgreSQL, subscribe to our newsletter, or follow us on Twitter, Facebook, or LinkedIn.
+43 (0) 2622 93022-0
office@cybertec.at
You are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from X. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information